3주 동안 연속으로 진행될 미니 프로젝트에 머리가 어질어질하지만,,, 그만큼 많이 성장할 수 있는 기회라고 믿고! 이번 프로젝트도 최선을 다해보려고 했다...! 하지만 최고 난관에 봉착하였다. 정말루 에이블 스쿨을 시작하고 가장 힘들었던 한 주가 아닐까 싶다 ㅠ 딥러닝에 대해 배우는 게 처음이기 때문에, 기본적인 Sequential & Functional 모델도 신기했고 컴퓨터 비전과도 연관 있을 것 같은 이미지 탐지와 같은 것들을 알아가는 것도 재미있었다. 하지만… 자연어 처리… 최대 난관이다 ヾ( ·`⌓´·)ノ゙ 기본적인 개념도 확 들어오지 않고,, 솔직히 말하면 자연어 처리를 배우는 5일 동안 뭘 배운 건지 잘 모르겠다… 수업이랑 프로젝트랑의 갭 차이는 당연히 어느 정도 있어야 한다고 생각하긴 하지만 진도에 대해 많은 아쉬움도 있지만,, 프로젝트에서 새로 다루게 된 개념이 생각보다 단기간에 이해하고 적용하기가 힘들었다.. 형태소 분석기에 대해 언급이라도 지난주에 있었었으면 좋았을 텐데… 또한 보통 미니프로젝트 조원이 7~8명인데,, 이번 4차 프로젝트는 5명이서 진행하게 되었다. 인원이 다른 조들보다 훨씬 적어서 걱정도 많이 했는데, 그래도 나름 잘 마무리했다고 생각한다. 하여간 역대급 최고난도 프로젝트에 정신 못 차리고 허덕였던 생생한 후기를 남겨보겠다. Σ(; ・`д・´)
미니프로젝트 4차 : AIVLE-EDU 1:1 문의 유형 분류하기
1일차 : 데이터 전처리
에이블스쿨 교육에서 사용하는 AIVLE-EDU 홈페이지에는 수업을 진행하면서 수강생들이 모르는 것이나 도움이 필요할 때 손쉽게 요청할 수 있는 일대일문의가 존재한다. 나도 프로젝트하다가 종종 막히는 게 있으면 1대1 문의를 사용해서 질문을 하기도 하는데, 질문할 때 문의 유형을 직접 선택할 수 있도록 되어 있다. 그러면 튜터 분들이 질문의 유형에 따라 원격 지원 및 답안을 직접 작성하기도 하고, 관련 담당자에게 전달하는 업무를 한다고 한다. 이런 과정을 효율적으로 운영하기 위해서는 질문의 카테고리가 제대로 작성되어야 적절한 담당자에게 배치될 수 있기 때문에, 자연어처리 모델을 통해 질문을 올바른 유형으로 분류하는 모델을 만드는 것이 이번 프로젝트의 목표이다. 제공된 데이터는 우리 이전 기수인 2기의 질문들을 모아서 만들어졌고, 문의 유형은 크게 6가지로 나눌 수 있었다.
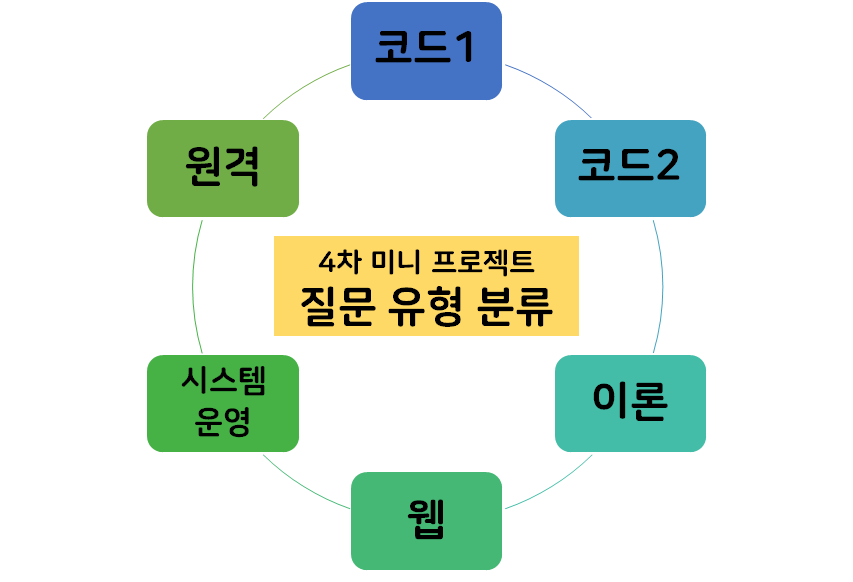
다양한 형태의 텍스트 데이터 입력을 알맞은 문의 내용으로 분류하면 되는 것이었다. 이전 프로젝트와 동일하게 데이터 전처리 → 모델 학습을 진행하고, 마지막 5일차에는 kaggle competition을 진행한다. 첫 kaggle때 상위 70% 이내에 들었으므로, 이번에는 50%에 들고 싶다는 작은 목표가 있다..!!
▶ 1일차 일정 : 개별 실습 → 조별 토의 및 실습
데이터 전처리가 이틀에 걸쳐 진행되는데,,, 첫날부터 멘붕파티였다. 물론 실습과 프로젝트는 다르기에 교육 때 배운 내용만 순수하게 다루지 않는다는 것을 알지만, 교육과 프로젝트 간의 차이가 이번에 정말 크게 느껴졌다. EDA 했던 때와 비교하면 사실 데이터 전처리 '과정' 자체는 단순해졌는데 새로운 패키지 사용법을 익히고 적용하는 건 쉽지 않다. 그리고 아마 코드가 잘못된 것 같긴 한데 전처리 과정에서 단순히 형태소 분석하는 코드가 30분을 실행시켜도 끝나지 않았다... 전체 데이터중에 약 3%를 처리할 때 12초가 걸리는데 100% 데이터를 처리하는데 30분이 지나도 안 끝난다면,,, 내 잘못이 분명할 거야 😥 조별 실습 시간에 한 게 부족해서 많이 참여할 수가 없는 게 아쉬웠다.. 저녁에도 계속 시도해 봤는데 큰 진전은 없어서 내일 아침에 강사님이 코드 리뷰 해주실 때 다시 한번 잘 살펴봐야겠다.
2일차 : 데이터 전처리 1
▶ 2일차 일정 : 개별 실습 → 조별 토의 및 실습
오전에 코드 리뷰를 진행해 주셔서, 좀 더 명확하게 프로젝트에 대해 이해하고 전처리를 진행하였다. 문장이나 코드로 이루어져 있을 입력 데이터를 분석하기 위해 최단/최장길이의 문장을 살펴보기도 하고, 다양한 형태소 분석기를 적용하여 단어를 추출해 보았다. 똑같은 문장이라도, 형태소에 따라 다른 결과를 보인다. 이런 걸 확인하기 위해, 4가지 형태소 분석기와 3가지의 각기 다른 분석(명사, 형태소, 형태소+명사) 단위를 적용해 보았다.

같은 문장이지만, 분석기에 따라 문장을 형태소로 쪼개거나, 어떤 것들을 명사로 인식하는지 이런 부분에서 차이를 보이는 것을 알 수 있다. kkma라는 형태소 분석기를 단순히 ‘들어본 적’ 있어서 그걸 사용할까 하다가, 대부분 Mecab을 통해 형태소 분석을 진행하여서 나는 청개구리 심보 발동으로 트위터(okt) 형태소 분석기를 쭉 사용하였다. 이렇게 형태소 분석기를 통해 각 단어마다 해당되는 품사를 출력하는 품사 태깅과, 명사 추출을 진행하였다. 처음 보는 개념이 많아서 이론적인 부분들을 탐색하는데 헤매기도 하여서 시간을 많이 사용하기도 했다.
3일차 : 데이터 전처리 2
▶ 3일차 일정 : 개별 실습 → 조별 토의 및 실습
3일차의 시작은 NLTK를 이용한 텍스트 전처리였다. NLTK는 자연어 처리 및 문서 분석을 위한 교육용 파이썬 패키지이다. 전날에 사용한 형태소 분석기나 품사 태깅, 명사 추출은 Knolpy라는 한국어 정보처리에 특화된 파이썬 패키지를 사용한 것이었다. 한글로만 이루어진 텍스트에서는 Knolpy 내부의 형태소 분석기를 사용하여도 충분할 수도 있지만, 에이블 에듀의 1대1문의 속 질문들은 아무래도 한글로만 이루어져 있다기 보단 질문할 코드나 개념에 대해서 언급하기 위해 영어도 포함되어 있는 경우가 비일비재할 것이다. 단일언어만을 취급하는 모델보다, 여러 언어를 모두 인식하고 분류하는 게 참 어려울 것 같다. 특히 한국어랑 영어는 문법적인 부분에서는 접점이 크지 않기 때문에 이런 게 자연어 처리에도 일부 문제가 될 수 있겠다 싶기도 하다. 하지만 요새 파파고 번역만 봐도 엄청난 퀄리티를 자랑하던데, 이미 다양한 언어를 골고루 학습한 모델도 충분히 많지 않을까 싶다! 어쨌든 2일차는 텍스트 분석을 더 진행하였다. 사실 주어진 파일 속 설명들이 한 번에 이해 가지가 않았던 게 많아서 어려웠다 ㅠ 가이드라인이 잡혀 있지만, 잘 모른 채로 따라가려고 하니 금방 되지는 않았다. 그래도 주어진 설명을 참조하여 데이터 전처리를 계속 진행하였다.

만들고 나니 뿌듯했던 Word Cloud XD 등장한 단어의 빈도수를 시각화 한 그림이다! 전체적인 문의 내용에는 다음과 같은 단어들이 가장 빈번하게 나온다. 딱 봐도 값, 수, 코드, 파일, 실습, 함수 이런 단어들이 눈에 잘 띄는 것 같다!
이제 직접적으로 데이터는 X(feature)와 Y(target)으로 구분하고, 다양한 모델 적용을 위한 전처리를 진행했다. 특수문자 제거는 선택사항이었는데, 처음에는 제거했었다가 실제 코드에서는 =과 같은 여러 특수문자도 중요할 것 같아서 제거하지 않았다. 그 다음 X 데이터인 질문들에서, 명사 태깅으로 명사 단어들만 골라냈다. 그리고 그 데이터들을 N-gram & Sequence 형식으로 변환했다. N-gram으로 변환하기 위해 Count Vectorizer를 적용하였다. Sequence로 변환하기 위해, 첫번째로는 Tokenizer 모듈을 사용하고, padding을 적용하여 전체 텍스트 데이터의 길이를 통일해 주었다. 두 번째로는 TfidVectorizer 모듈을 사용하고, padding을 적용하였다. Count Vectorizer랑 Tokenizer에 대해 이해하기 위해서 많은 시간을 할애했다.
4일차 : 데이터 전처리 + Text Classification 머신러닝/딥러닝
▶ 4일차 일정 : 개별 실습 → 조별 토의 및 실습
전날 진행 중이던 N-gram / Sequence로의 변환을 마무리하고 본격적으로 머신러닝과 딥러닝 학습을 진행했다. 시간이 촉박하지만 어쩔 수 없었다. ( •_ •̥ ˳ ˳ )
머신 러닝 모델에 데이터를 넣어 학습하고 분류해 보았다. 데이터도 n-gram, Tokenizer+padding, TfidVectorizer+padding의 3가지 입력을 적절히 활용하였다. 모델 학습 할 때 내가 허무하다고 느끼는 모든 순간을 다 겪기도 했다… 데이터 전처리를 안 한 것이 데이터 전처리를 한 것보다 결과가 좋을 때, 신경 써서 파라미터를 정한 모델보다 파라미터 설정 없이 기본 상태 그대로 적용한 모델이 결과가 좋을 때 등등 ×͜×

특히 하이퍼파라미터를 다양하게 변경해보았는데 성능이 눈에 띄게 향상하는 경우는 거의 없었다. 지금 와서야 생각해 보면, 하이퍼 마라 미터 튜닝을 진행할 때 탐색할 변수들의 범위를 제대로 정하는 것도 중요한데 우선 이것저것 여러 개를 몰아서 넣고 좋은 결과가 나오기를 기다렸던 것 같다. 파라미터 튜닝 자체에는 익숙해졌는데, 아직 요령이 많이 부족한듯 하다. 하지만 사람 마음이란 게,, 시간이나 노력을 투자하면 그에 응당한 좋은 결과를 받고 싶어 한다! 아직 완벽하게 모든 걸 아는 상태가 아닌데 항상 좋은 결과만 바라는 것도 잘못되지 않았나 싶다! 갑작스럽지만 이런 나의 태도 반성합니다…
그리고 딥러닝 모델로도 학습을 진행해 보았는데, 아직까지 딥러닝에 대한 이해도가 부족해서 우선 실습 자료에 있는 모델이나, 구글을 참조해서 만들고 학습시켜보았다. 하지만 딱히 좋은 결과가 있지는 않았다.. 프로젝트를 해오면서 난 항상 머신러닝을 통한 분류가 일반 딥러닝을 통한 분류보다 정확성이 높았었다. 하지만 다른 조원들을 보니, 딥러닝 모델로도 좋은 결과를 많이 내셨다! 딥러닝 쪽이 많이 부족하니까 얼른 더 공부해서 채워야 하는데 프젝 기간에는 저녁에 녹초가 된다~
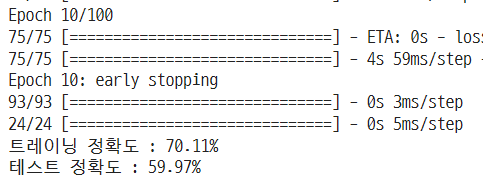
이날의 학습 결과를 바탕으로 나는 케글에서도 머신러닝 모델에 집중하기로 결정했다!
5일차 : Text Classification 실습 (Kaggle)
▶ 5일차 일정 : 조별 Kaggle Competition → 조별 발표
대망의 조별 케글 대회! 케글 대회 때는 보통 train data는 프로젝트 시작할 때 준 train data와 동일하다. 대신 새로운 test data를 제공하고, 이것을 질문 유형에 맞게 분류하는 것이 우리의 목표!
나는 데이터 전처리 부분에서는, 입력된 질문들을 okt의 morphs를 사용하여 모든 품사의 단어들을 사용하였다. 이후 한 글자로 이루어진 단어, 조사와 같은 단어들을 불용어로 간주하고 제외하였다. (ex) 은, 는, 이, 가, 것, 제, 안녕, 감사 …) 영어나 특수문자들은 제거하지 않았다.
케글 대회는 한 팀당 제출할 수 있는 시도 횟수를 20번으로 제한하기 때문에, 보통 프로젝트 때는 1인당 약 3번 제출할 수 있었다. (조원이 보통 7~8명이기 때문!) 하지만.. 불행(?) 중에 다행이라고 이번 프로젝트 조원이 나까지 5명이어서 4번 제출할 수 있었다 XD 그래서 사실 나는 오전에 빠르게 제출 횟수 3회를 사용하고, 오후에 추가적인 모델링을 더 하고 나은 결과를 낼 수 있을 것 같으면 제출하려고 했다. 정확도가 0.8 정도 나왔는데, 더 개선되지 않았다는 게 아쉬웠다.
작은 여담으로, 점심시간에 IT 트렌드 스터디원 분들도 처음 실물로 만났다 ^~^ 분당으로 오시는 분이 나 말고도 3분이나 계셔서 점심시간에 뵀다 ㅎ 딱 오늘 하루 반을 다른 곳으로 골라서 DX반 속에서 케글을 진행했는데, 복작복작하고 좋기도 하고 스터디원 한 분도 그곳에 계셨었다 ㅇ0ㅇ 신기방기! 이런 작은 재미도 있고 좋았다 ^~^
오후에도 으쌰으쌰 하면서 케글을 진행했다. 우리는 0.85 정도의 정확도로 대회를 마쳤고, 1,2등 조는 정확도가 0.90를 넘겼다!! 프로젝트 점수 커트라인이 30등까지여서 마지막까지 굉장히 조마조마해했다 ㅋㅋㅋ 이번 프로젝트가 개인적으로는 너무 어렵게 느껴졌어서, 조별 발표 시간이 정말 기다려졌다~ 다른 좋은 결과를 낸 조들은 어떤 방식을 활용했는지 너무 궁금했는데, 크게 복잡하지 않지만 야무진 전처리도 좋은 정확도를 낸 팀들을 보면서 많은 것들을 배웠다.

총평
힘든 프로젝트 속에서도 프로젝트 외적으로 흥미로운 상황들이 많이 있었어서 나름 재미있는 한 주였다. 이번에 공모전에 참가하게 되었는데, 4인 1조인 공모전에서 3명이 프로젝트 같은 조로 배정이 된 것도 엄청난 우연이 아닐까 싶다. 그리고 아무리 생각해 봐도 이번 주 강사님 뭔가 공대생의 냄새가 난다 ㅋㅋㅋㅋ 무언가 설명할 때 눈이 반짝반짝 빛나고 설명을 마치면 ‘이런 거 너무 신기하고 재밌지 않나요~’ 학생들한테 반문하시는데 약간 대학에서 본 젊은 교수님들과 흡사한 느낌이었다. 하지만 그때마다 학생들은 울고 있었다 ㅋㅋㅋㅋㅋㅋ 줌에서 우는 이모지를 제일 많이 본 한 주였다고 해도 과언이 아니다… 사실은,,, 그때 저도 같이 우는 이모지 연타했었습니다 🤣🤣 그리고 이번 프로젝트를 진행하는 한 주 동안 가장 핫했던 단어가 하나 있다고 할 수 있다. 바로 “개추” 진짜 익명 설문조사할 때 너무 웃겼다 ㅋㅋㅋㅋㅋㅋ 역시 우리나라.. 해학의 민족이라 그런지 어려워서 멘붕이었던 프젝 속에서 좀 웃을 수 있었다 ㅎ 근데 나도 개추가 개같이 추천의 줄임말인 줄 알았는데 개념글 추천이었다는 걸 처음 알았다! 뭐 어쨌든 이번 프로젝트 그래도 배워가는 게 있었으면 개추 👍
자연어 처리라는 분야 자체도 굉장히 어려운 것 같고, 자연어 처리를 위한 데이터 전처리 과정이나 모델 생성도 익숙하지 않은 게 많아서 어려웠지만 이번 기회를 통해 내가 부족한 부분에 뭐가 있는지 뼈저리게 느꼈으니 앞으로 더 성장할 일만 남았지 않은가 싶다! 3주 동안 연속으로 프로젝트가 진행되는데 첫 주부터 이렇게 진땀을 빼서 남은 2주 잘 버틸 수 있을지 약간 걱정되기도 한다! 체력 관리를 항상 열심히 해야 될 것 같다. 프젝도 엉덩이 싸움이다!! 그래도 다시 힘내서 다음 주 프로젝트 때 더 좋은 결과를 낼 수 있으면 좋겠다 ♪( 'ω' و(و”
'KT AIVLE School 3기' 카테고리의 다른 글
| [KT AIVLE School 3기] 6차 미니 프로젝트 후기 (1) | 2023.04.22 |
|---|---|
| [KT AIVLE School 3기] 5차 미니 프로젝트 후기 (1) | 2023.04.17 |
| [KT AIVLE School 3기] 3차 미니 프로젝트 후기 (0) | 2023.03.25 |
| [KT AIVLE School 3기] 2차 미니 프로젝트 후기 (0) | 2023.03.17 |
| [KT AIVLE School 3기] 1차 미니 프로젝트 후기 (0) | 2023.03.12 |